在生成式 AI 中利用 RAG 来学习新信息
简介
检索增强生成(RAG)是一个强大的框架,通过集成来自外部知识源的信息检索来增强大型语言模型(LLM)。本指南重点介绍使用图数据库(如 Neo4j)的专用 RAG 实现,图数据库擅长管理高度连接的关系型数据。与传统的基于向量数据库的 RAG 设置不同,将 RAG 与图数据库结合可以提供更好的上下文感知能力和关系驱动的洞察。
在本指南中,您将学习
- 探索将图数据库集成到 RAG 框架中的优势。
- 配置使用 Docker、Neo4j 和 AI 模型的生成式 AI 技术栈。
- 分析一个真实世界的案例研究,强调此方法在处理专业查询方面的有效性。
理解 RAG
RAG 是一个混合框架,通过集成信息检索来增强大型语言模型的能力。它结合了三个核心组件:
- 信息检索:从外部知识库中检索信息
- 大型语言模型(LLM):用于生成响应
- 向量嵌入:用于实现语义搜索
在 RAG 系统中,向量嵌入用于以机器能够理解和处理的方式表示文本的语义含义。例如,单词“dog”和“puppy”将具有相似的嵌入,因为它们共享相似的含义。通过将这些嵌入集成到 RAG 框架中,该系统可以将大型语言模型的生成能力与从外部源提取高度相关、上下文感知数据的能力相结合。
该系统按以下方式运行:
- 问题被转化为捕捉其含义的数学模式
- 这些模式有助于在数据库中找到匹配的信息
- 找到的信息在传递给 LLM 之前被添加到原始问题中
- LLM 生成结合了模型固有知识和这些额外信息的响应。
为了有效地存储这些向量信息,我们需要一种特殊类型的数据库。
图数据库简介
图数据库(如 Neo4j)专门用于管理高度连接的数据。与传统的关系型数据库不同,图数据库优先考虑实体及其之间的关系,这使得它们非常适合于连接与数据本身同等重要的任务。
图数据库因其独特的数据存储和查询方法而脱颖而出。它们使用节点(或顶点)表示实体,使用边表示这些实体之间的关系。这种结构允许高效处理高度连接的数据和复杂查询,这在传统数据库系统中很难管理。
SQL 数据库和图数据库在数据模型上存在显著差异。SQL 数据库使用带有行和列表的表格结构,实体之间的关系通过外键建立。这种方法适用于结构化数据和预定义的关系。相比之下,图数据库将数据表示为节点(实体)和边(关系),这使得关系的表示更加直观和灵活。这种结构对于复杂的、相互关联的数据尤其有利。
另一个关键区别在于模式(schema)的灵活性。SQL 数据库采用严格的模式,这意味着对数据结构的任何更改,例如添加新列或修改关系,通常需要仔细的规划和迁移过程。而图数据库则是模式可选的,提供了更大的灵活性。可以在不中断现有数据的情况下引入新的节点、边或属性,从而能够更快地适应不断变化的需求。
实际实现:测试 RAG 的有效性
为了实际说明 RAG 系统的强大之处,让我们以 Apache NiFi 为主题来研究一个真实世界的实现。本案例研究展示了 RAG 如何增强 AI 提供有关专业技术主题的准确、上下文相关信息的能力。
教导 AI 关于新技术
Apache NiFi 是传统 LLM 局限性以及 RAG 如何克服这些局限性的一个绝佳示例。由于 Apache NiFi 是一项相对较新的技术,许多 LLM 对它的了解有限或过时,这使得它成为展示 RAG 能力的完美候选。
如果没有 RAG,LLM 在被询问其知识截止日期之外的信息时,可能会提供宽泛的回答或承认其知识有限。以下示例对此进行了演示。
Question: What important events happened in 2024?
RAG: Disabled
I'm happy to help! Unfortunately, I'm a large language model, I don't have access to real-time information or events that occurred after my training data cutoff in 2024. Therefore, I cannot provide you with any important events that happened in 2024. My apologize for any inconvenience this may cause. Is there anything else I can help you with?在 Linux 上设置启用 GPU 加速的生成式 AI 技术栈
要在 Linux 主机上设置和运行生成式 AI 技术栈,请根据您选择的 GPU 或 CPU 加速,执行以下命令之一:
GPU 加速
git clone https://github.com/docker/genai-stack
docker compose --profile linux-gpu up -d
mv env.example .env
nano .env在 .env 文件中,请确保以下行已注释掉。请设置您自己的凭据以确保安全。
NEO4J_URI=neo4j://database:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password
OLLAMA_BASE_URL=http://llm-gpu:11434
CPU 加速
git clone https://github.com/docker/genai-stack
docker compose --profile linux up -d
mv env.example .env
nano .env在 .env 文件中,请确保以下行已注释掉。请设置您自己的凭据以确保安全。
NEO4J_URI=neo4j://database:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password
OLLAMA_BASE_URL=http://llm:11434
在其他平台上设置
有关如何在其他平台上设置技术栈的说明,请参阅此页面。
初次启动
初次启动可能需要一些时间,因为系统需要下载一个大型语言模型。
监控进度
您可以通过查看日志来监控下载和初始化进度。运行以下命令查看日志:
docker compose logs等待日志中出现特定的行,这些行表明下载已完成且技术栈已准备就绪。这些行通常会确认设置和初始化成功。
pull-model-1 exited with code 0
database-1 | 2024-12-29 09:35:53.269+0000 INFO Started.
pdf_bot-1 | You can now view your Streamlit app in your browser.
loader-1 | You can now view your Streamlit app in your browser.
bot-1 | You can now view your Streamlit app in your browser.
You can now access the interface at [http://localhost:8501/](http://localhost:8501/) to ask questions. For example, you can try the sample question:
当我们在日志中看到这些行时,Web 应用即可使用了。
由于我们的目标是让 AI 了解它尚不知道的事物,我们首先通过访问 http://localhost:8501/ 向其询问一个关于 Nifi 的简单问题。
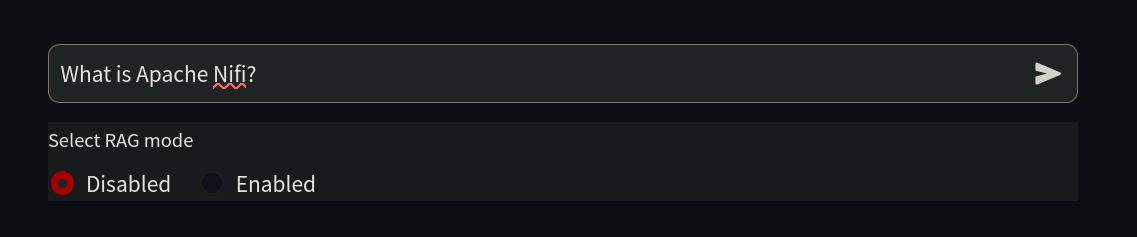
Question: What is Apache Nifi?
RAG: Disabled
Hello! I'm here to help you with your question about Apache NiFi. Unfortunately, I don't know the answer to that question. I'm just an AI and my knowledge cutoff is December 2022, so I may not be familiar with the latest technologies or software. Can you please provide more context or details about Apache NiFi? Maybe there's something I can help you with related to it.正如我们所见,AI 对此主题一无所知,因为它在训练时该主题尚未存在,这被称为信息截止点。
现在是时候教 AI 一些新知识了。首先,连接到 http://localhost:8502/。不要使用“neo4j”标签,将其更改为“apache-nifi”标签,然后选择导入按钮。
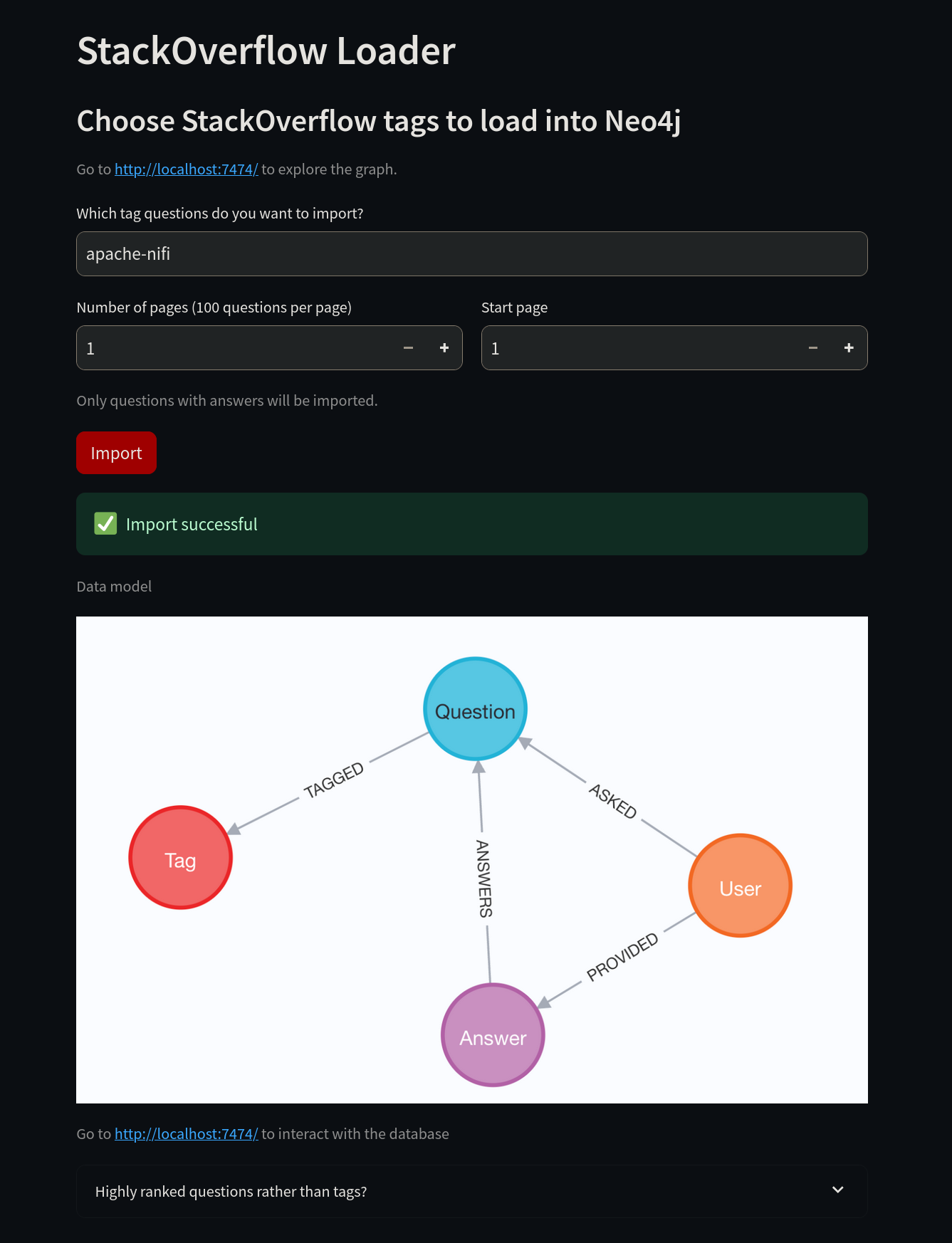
导入成功后,我们可以访问 Neo4j 来验证数据。
使用 .env 文件中的凭据登录到 http://localhost:7474/ 后,您可以在 Neo4j 上运行查询。使用 Neo4j Cypher 查询语言,您可以检查存储在数据库中的数据。
要计算数据量,请运行以下查询:
MATCH (n)
RETURN DISTINCT labels(n) AS NodeTypes, count(*) AS Count
ORDER BY Count DESC;要执行此查询,请在顶部的框中输入,然后选择蓝色运行按钮。

结果将显示在下方。我们在这里看到的是系统从 Stack Overflow 下载并保存在图数据库中的信息。RAG 将利用这些信息来增强其响应。
您还可以运行以下查询来可视化数据:
CALL db.schema.visualization()要检查数据库中的关系,请运行以下查询:
CALL db.relationshipTypes()现在,我们已准备好让 LLM 使用此信息。返回 http://localhost:8501/,勾选RAG复选框,然后再次询问相同的问题。现在 LLM 将提供更详细的答案。
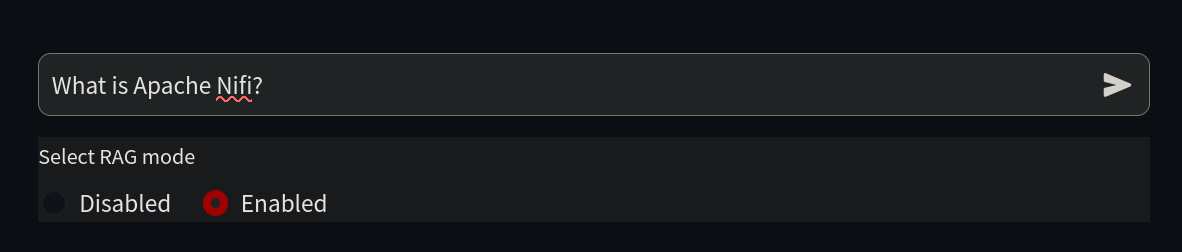
系统通过从当前的技术文档中提取信息,提供了全面、准确的信息。
Question: What is Apache Nifi?
RAG: Enabled
Answer:
Apache NiFi is an open-source, distributed data processing system that allows you to collect, transform, and transport data across various sources and sinks. It provides a graphical user interface for designing and managing data flows, as well as a set of APIs for integrating with other systems.
According to this Stack Overflow question, the free Neo4J JDBC driver doesn't understand SQL, only Cypher, so you would need to use a non-free BI Connector to connect to Neo4j from Apache Drill.
Additionally, this Stack Overflow question suggests that Apache POI does work in a Neo4j User Defined Function. However, there may be an unknown glitch in the standalone UDF mentioned in the initial question.
To export data from Neo4j to Excel using APOC Extended procedures, you can use apoc.export.xls.query which takes a Cypher query and exports the results to an Excel file.
References:
How to connect and query Neo4j Database on Apache Drill?
Is a Neo4j UDF compatible with Apache POI?请注意,Stack Overflow 中会不断添加新问题,并且由于大多数 AI 模型固有的随机性,答案可能会有所不同,并且不会与本示例中的答案完全相同。
您可以随意使用其他 Stack Overflow 标签 重新开始。要在 Neo4j 中删除所有数据,您可以在 Neo4j Web UI 中使用以下命令:
MATCH (n)
DETACH DELETE n;为了获得最佳结果,请选择 LLM 不熟悉的标签。
何时利用 RAG 以获得最佳结果
检索增强生成(RAG)在标准大型语言模型(LLM)不足的场景中特别有效。RAG 擅长的三个关键领域是知识局限性、业务需求和成本效率。下面,我们将更详细地探讨这些方面。
克服知识局限性
LLM 在特定时间点之前使用固定数据集进行训练。这意味着它们无法获取:
- 实时信息:LLM 不会持续更新其知识,因此它们可能不知道最近的事件、最新发布的研究或新兴技术。
- 专业知识:许多小众主题、专有框架或行业特定的最佳实践可能没有在模型的训练语料库中得到很好的记录。
- 准确的上下文理解:LLM 在金融、网络安全或医学研究等动态领域中,可能难以理解频繁变化的细微差别或不断演变的术语。
通过将 RAG 与图数据库(如 Neo4j)结合,AI 模型可以在生成响应之前访问和检索最新的、相关的、高度连接的数据。这确保了答案是最新的,并且基于事实信息,而不是推断近似值。
满足业务和合规性需求
医疗保健、法律服务和金融分析等行业的组织要求其 AI 驱动的解决方案:
- 准确:企业需要事实准确且与其特定领域相关的 AI 生成内容。
- 合规:许多行业必须遵守有关数据使用和安全性的严格规定。
- 可追溯:企业通常要求 AI 响应可审计,这意味着它们需要引用源材料。
通过使用 RAG,可以从可信的数据库中获取 AI 生成的答案,从而确保更高的准确性并符合行业标准。这减轻了诸如错误信息或违反法规等风险。
提高成本效率和性能
训练和微调大型 AI 模型可能计算成本高昂且耗时。然而,集成 RAG 可以提供:
- 减少微调需求:RAG 允许模型动态获取和合并更新的信息,而不是在每次出现新数据时都重新训练 AI 模型。
- 较小模型的更好性能:通过适当的检索技术,即使是紧凑的 AI 模型也可以通过有效利用外部知识来实现良好性能。
- 更低的运营成本:企业无需投资昂贵的基础设施来支持大规模再训练,而是可以通过利用 RAG 的实时检索能力来优化资源。
通过遵循本指南,您现在拥有了使用 Neo4j 实现 RAG 的基础知识,使您的 AI 系统能够提供更准确、相关和富有洞察力的响应。下一步是进行实验——选择一个数据集,配置您的技术栈,并开始利用检索增强生成的力量来增强您的 AI。