Docker 构建缓存
目录
当您多次构建同一个 Docker 镜像时,了解如何优化构建缓存是确保构建快速运行的绝佳工具。
构建缓存的工作原理
理解 Docker 的构建缓存有助于您编写更好的 Dockerfile,从而实现更快的构建。
以下示例展示了一个用 C 语言编写程序的简短 Dockerfile。
# syntax=docker/dockerfile:1
FROM ubuntu:latest
RUN apt-get update && apt-get install -y build-essentials
COPY main.c Makefile /src/
WORKDIR /src/
RUN make build此 Dockerfile 中的每条指令都转换为最终镜像中的一个层。可以将镜像层视为一个堆栈,每个层都在其之前的层之上添加更多内容。

每当某个层发生变化时,该层就需要重新构建。例如,假设您修改了 main.c 文件中的程序。更改后,COPY 命令将需要再次运行,以便这些更改出现在镜像中。换句话说,Docker 将使此层的缓存失效。
如果一个层发生变化,其后的所有其他层也会受到影响。当包含 COPY 命令的层失效时,其后的所有层也需要再次运行。
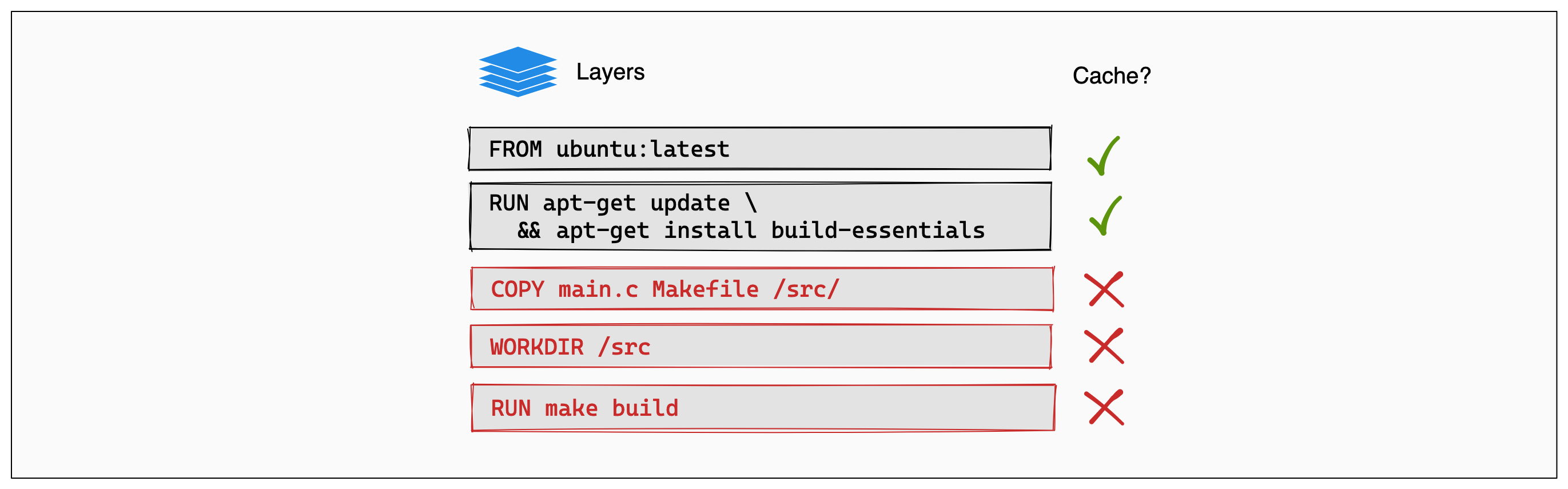
这就是 Docker 构建缓存的精髓。一旦某个层发生变化,其后的所有下游层也需要重新构建。即使它们的构建结果没有不同,也需要重新运行。
其他资源
有关使用缓存进行高效构建的更多信息,请参阅